
Intended Audience
I have tried creating a simple many to one request/response(asynchronous) service application using Kafka messaging and Kafka Streams to demonstrate its capabilities as messaging and streams processing.
This post is intended for audiences
- familiar with Kafka messaging and Kafka Streams theoretically and wants to visualize it better using an industry example
- want to understand setting up Kafka development environment on their development machines and write some code to play hands-on (Part 2)
Use Case
A Global bank has a global account service application that provides an interface to fetch the customer’s account information.
Various client applications across the bank require to consume this service to fetch customer details, Ex:- mobile app, UPI app, retail banking platform, corporate banking platform, etc.
Global accounting service has its own request/response message/API contract.
This is a hybrid model where account service is on the latest technologies like API based and uses Kafka infrastructure to communicate where many clients are still monolithic and use conventional messaging channels like IBM MQ.
Following points to consider
- All applications having connectivity using messaging technologies like IBM MQ
- Multiple client applications built on different technologies
- Client applications have their own request format, Example: vendor’s products having their own format of request generation
- Accounting service application has its own request-response format
- The need for message format transformation between the client application and accounting service application for request as well as response flow
Kafka messaging and Kafka Streams in action
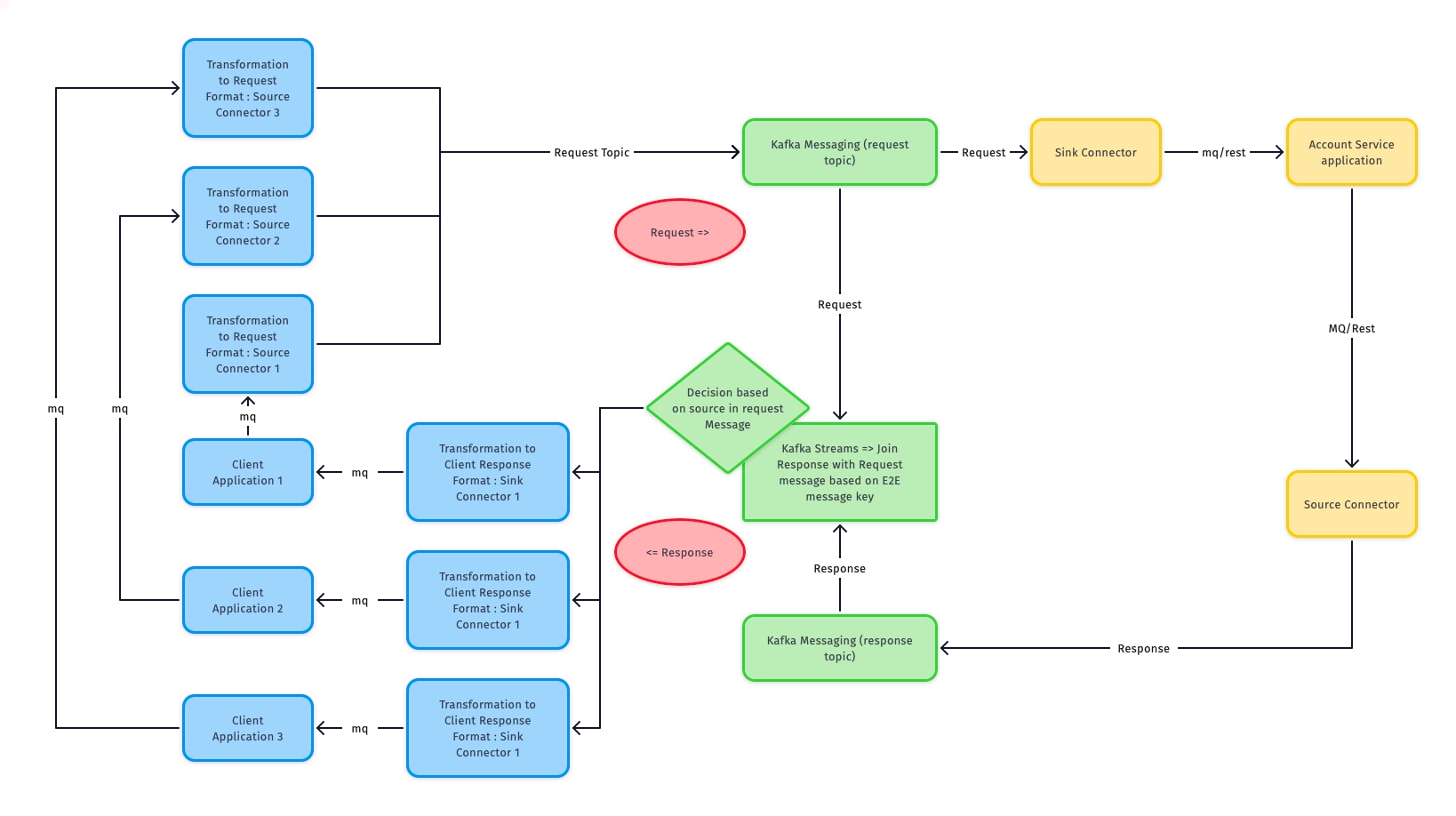
Request flow
Option 1: Kafka confluence (https://www.confluent.io/product/confluent-platform) license available
- Source connector is used to connect client application, it pools message continuously – provides out of the boxes transformation classes for standard formats, Custom classes to be developed for proprietary formats
- Once the message is transformed and sent to request topic by source connector which will be picked up by sink connector and submitted to accounting service
- Add source client application information in the request message header
Option 2: Kafka Confluence license not available – using standard Kafka open source libraries (https://kafka.apache.org)
- Requires custom code to connect a client application (Ex: message-driven beans – MDB) to fetch messages
- Code transformation service will be developed to format message in accounting service application API format
- Add source client application information in the request message header and after message transformation produce to request topic using Kafka producer library
Response Flow
- Accounting service will provide a response as per its response API contract
- A Kafka Streams application will consume response from response topic
- Kafka stream application will perform a join of request message stream to response message stream using e2e message key which can be set as Kafka message key in request and response
- The way Kafka handles is that once records join returns a row that response offset is committed and the record is passed for streams processing
- From request, the message finds source client application details and route the response message to the corresponding client application.
- Results can be stores as Kafka streams or Kafka global tables based upon implementation
- Sink connector (confluent/custom) will transform back the response to their corresponding client application format
Additional points
- Manage topic data retention policy to optimum as per system requirement so that Kafka Streams joins perform faster
- For audit use a separate queue where data can be dumped for a longer period or sent to audit systems connected to audit topics
- For confluent an alternative to Kafka stream code will be using KSql which internally works using Kafka Streams – KSql has SQL-like interface using which we can define SQL to join streams and start & maintain it like a service.
Benefits
- Kafka provides in-house logging capability and hence there is no need for an additional layer of service bus to records messages flow
- Message log retention period is configurable
- Open source Kafka can be used to configure most of the solution required
- Pretty scalable and fault-tolerant as Kafka is a highly scalable and distributed system
- Practically messages delivery guarantee for every consumer – it depends on how well you set up your Kafka infrastructure, topic partitions, topic replication factor, etc.
Source code
Next post Part 2/2 contains the following :
- Setting up Kafka development environment at the local machine
- Sample code git bucket link
- A post explaining main code snippets.
Closing note
- I would appreciate constructive comments/queries over this post.
- Let’s not discuss other solutions/more efficient solution using other technologies – there is always one. The intention here is to explain Kafka messaging & Kafka Streams the capabilities using a simple industry example


